You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
1.7 KiB
1.7 KiB
作业报告
1. 基本的kMeans方法
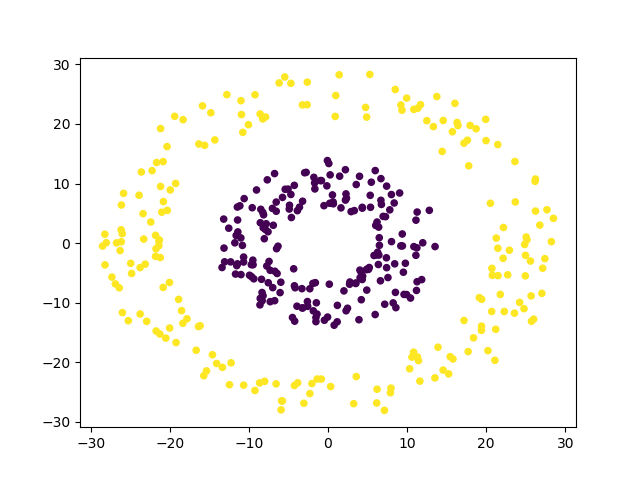
首先我编写了一个最基础的kMeans类,聚类方法采用简单的离最近重心进行归类,并且不进行任何映射。原始数据点如下所示:
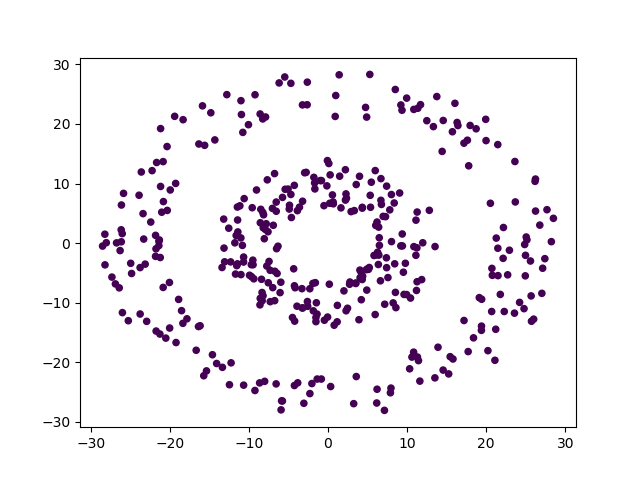
采用基础的kMeans方法分成两类后的结果如下所示:
2. 对原始数据进行变换
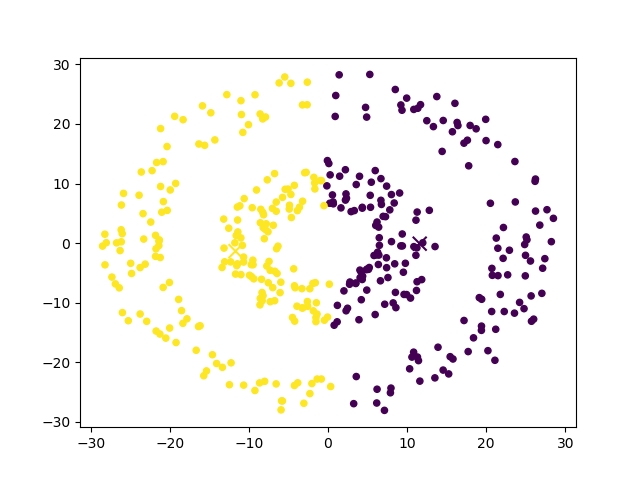
对原始数据点进行分析后,觉得可以将原始点映射到一个离(0, 0)点距离的空间中去,同样对数据归为两类,最终运行结果如下所示:
可以看到,通过对原始点进行变换后,归类后的效果更好。
3. 其他聚类方法
除了上述简单的聚类方法后,我还通过查找资料学习了到了一种根据密度进行聚类的方法,其核心思想是认为同一类别的样本,它们之间应该是紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在,通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。其伪代码如下:

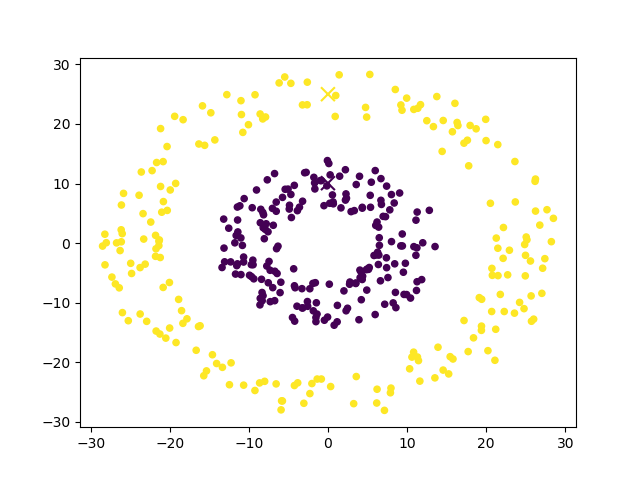
密度聚类不需要提前给定分类数,但其对参数eps和minPts比较敏感,如果选取不当,可以不能将数据点归类开,或者归类质量较低。对于给定的数据,在对参数多次尝试后,最后发现当eps=5,minPts=5时聚类效果不错,运行结果如下所示: