# 第五次作业报告
## 1. 全连接神经网络
> 对于一个全连接神经网络,需要存储每一层上的值以及层与层之间的权重项与偏置项。每一层上使用的激活函数类型以及最终输出层的代价函数可以额外定义。
### 1.1 函数版
当使用函数来实现全连接神经网络时,我们定义了一个字典来存储神经网络的信息,其结构如下:
```python
NN = {'nodes_size': [ ],
'layers': [ ],
'w': [ ],
'b': [ ]}
```
其中`nodes_size`记录每一层的节点个数,`layers`中则记录每一层通过正向计算得到的值,`w`存储各层节点与节点连接的权重矩阵,`b`存储各层节点之间连接的偏置项。
函数版本的实现仅考虑了激活函数为`sigmoid`函数的情形,输出的代价函数选为均方根误差$E_d = \frac{1}{2}\sum\limits_{i\in outputs}(t_i-y_i)^2$。正向传播的公式为:
$$
\vec{a} = f(W \cdot \vec{x})
$$
其中$f$为激活函数,$W$是某一层的权重矩阵,$\vec{x}$为某层的输入向量,$\vec{a}$为某层的输出向量。
反向传播使用梯度下降法更新权重矩阵与偏置项的误差计算公式为:
- 对于输出层节点$i$
$$
\delta_i = y_i(1-y_i)(t_i-y_i)
$$
其中,$\delta_i$是节点$i$的误差项,$y_i$是节点$i$的输出值,$t_i$是样本对应于节点$i$的目标值。
- 对于隐藏层节点$i$
$$
\delta_i = a_i(1-a_i)\sum_{k\in outputs} w_{ki}\delta_i
$$
-
更新权重矩阵与偏置项的公式如下:
$$
\begin{aligned}
w_{ji} &= w_{ji} + \eta\delta_j x_{ji} \\
b_{j} &= b_{j} + \eta\delta_j
\end{aligned}
$$
### 1.2 类版
使用类来实现全连接神经网络与函数版类似,只不过类版本将神经网络的数据结构存储到类属性中。同时,在类版本中,支持将输出层的激活函数指定为$sigmoid$函数或$softmax$函数。当输出层的激活函数为$sigmoid$函数时,输出层的代价函数选为均方根误差,权重矩阵与偏置项的更新公式与函数版一致。当输出层的激活函数为$softmax$时,输出层的代价函数选为$cross entropy$,此时,隐藏层的激活函数依旧为$sigmoid$函数,所以隐藏层的权重矩阵与偏置项的更新公式不变,而输出层的权重函数与偏置项的误差公式发生了一些变化,更改为:
- 对于输出层节点$i$
$$
\delta_i = t_i-y_i
$$
其余公式保持不变。
### 1.3 二分类运行结果
使用moons数据集来测试自己实现的二分类神经网络程序,生成的样本数为400,其中200个用于训练神经网络,剩下的200用于测试神经网络的预测精度,神经网络的输入层至输出层各层的节点个数布置为[2, 8, 2],预测结果如下:
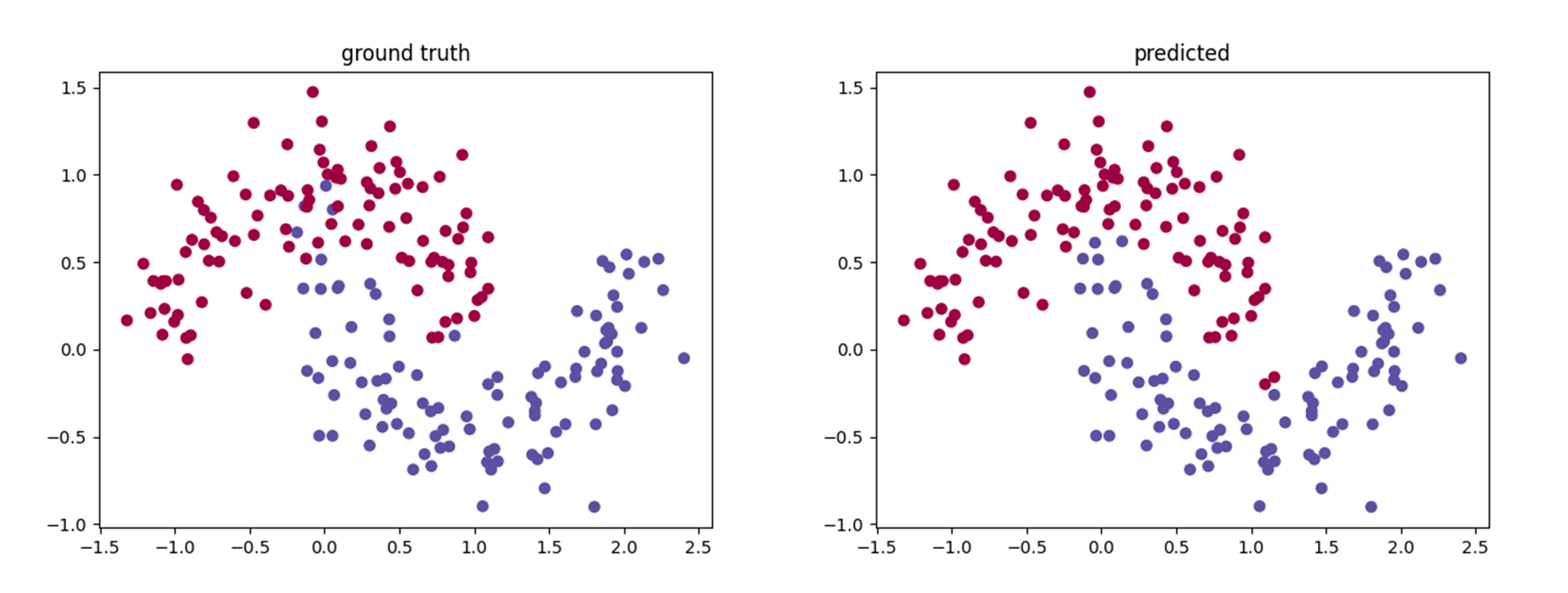
图1. 二分类预测(左图为真值,右图为预测值)
训练集上的代价函数值$Loss=0.0218$, 精度为$0.975$;测试集上的代价函数值$Loss=0.0357$,精度为$0.95$。从图上以及计算出来的代价函数值以及精度中可以看出,自己实现的神经网络预测精度较好,也验证了程序的可靠性与正确性。
### 1.4 多分类运行结果
多分类选用digits数据集,分别使用`sigmoid`作为输出层的激活函数以及均方根误差作为代价函数和使用softmax函数作为输出层的激活函数以及交叉熵作为代价函数训练神经网络并预测输出。将digits数据集中后500个样本作为测试数据集,其余样本作为训练数据集。神经网络各层的节点的个数为[64, 100, 10]。当输出层的激活函数为sigmoid函数时,confusion matrix如下:
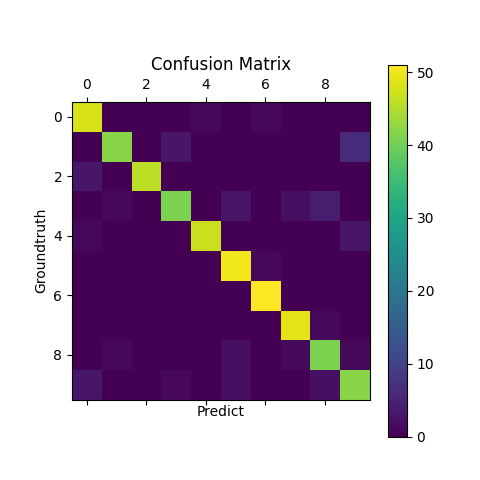
图2. 输出层为sigmoid函数时的confusion matrix
训练集上的精度为$0.984$,测试集上的精度为$0.914$。
采用相同的学习速率以及迭代次数,把输出层的激活函数改为softmax函数,代价函数改为交叉熵,再次运行程序,此时得到的confusion matrix如下:
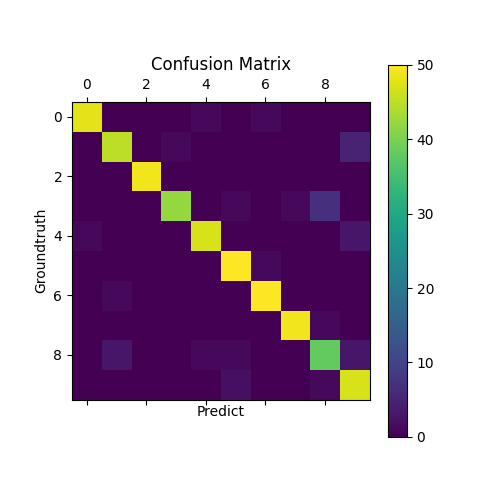
图3. 输出层为softmax函数时的confusion matrix
训练集上的精度为$1.0$,测试集上的精度为0.932。使用softmax作为激活函数,交叉熵作为代价函数的神经网络训练速度相比sigmoid作为激活函数,均方根误差作为代价的神经网络要快,在相同学习率以及迭代系数下,训练精度更高。
此外,使用softmax作为输出层的激活函数还可以输出类别所属概率。例如,对于某个标记为0的样本, 其输出的各个类别的概率为:
```json
{
'0': 9.95483984e-01,
'1': 9.19425256e-07,
'2': 4.72022568e-08,
'3': 2.89148627e-09,
'4': 1.12535172e-04,
'5': 1.93048146e-05,
'6': 4.29473472e-03,
'7': 4.89099761e-08,
'8': 8.24803816e-05,
'9': 5.94287548e-06
}
```
可以看到预测结果中,归属为`0`的概率远大于其他的概率,与真值情况相符。
### 1.5 与sklearn的运行结果对比
使用sklearn库实现上述全连接神经网络,层数以及节点的布置与上述描述的多分类神经网络相同。同样使用digits数据集进行测试,训练集与测试集选取与上述相同,最终预测的confusion matrix如下:

图4. sklearn实现的神经网络预测结果的confusion matrix
预测精度为$0.934$,从精度上来看,与自己实现的神经网络预测的结果精度基本相同,但从速度上来说,sklearn实现的神经网络比自己实现的神经网络快一些。